Parallel Execution in ANKHOR FlowSheet
While Moores law is still intact, one can easily observe that there has been a plateau reached at the performance improvements due to an increase in GHz. Modern CPUs are still becoming faster with each generation, but not so much due to an increase in clock speed, but improvements in the area of parallelism. Modern software should thus be written in a way to augment all levels of parallelism provided by state of the art CPUs. ANKHOR has been designed with parallelism in mind, and this article will provide some insight on the various levels at which this is achieved.
Parallel execution due to Data Flow architecture
ANKHOR uses data-flow architecture and thus generates a significant amount of coarse grain parallelism by design.
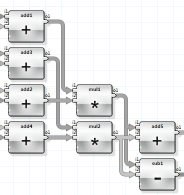
Operators are available for execution as soon as all of their inputs are available. ANKHOR uses as many parallel solver threads as provided by the CPU architecture to achieve a maximum utilization of CPU resources. Large FlowSheets provide a high level of data flow parallelism, and this is further improved by the built in optimizer of ANKHOR that performs operations such as loop unrolling, macro expansion or partial recursive evaluation to increase the size of an operator graph.

Parallelism due to Table Processing
ANKHOR operators are frequently used to process complete tables in one invocation. This is usually performed using a cell by cell approach, and can thus easily be parallelized. Operators that are processing large tables will split this work into independent chunks and execute them using as many processing threads as available.
This automatic split significantly improves the processing of large data sets.
Some operations, such as column compression, which have a dependency between the rows of the table, split the workload by columns instead of rows.
Non table operations e.g. exploding a string at a token or converting from CSV to table work on large string segments.
Loop Parallelism
Another great source for parallel execution opportunities are loops or tree style recursive invocation. ANKHOR executes loops with independent iterations and recursive invocations in a fully parallel way. Up to the number of processor thread iterations are activated at loop entry and each finished iteration starts a new one. This guarantees that there is enough work available to keep the CPUs busy.
Unfortunately this is not possible with loops that have dependent iterations. A sum of rows would be such a case.
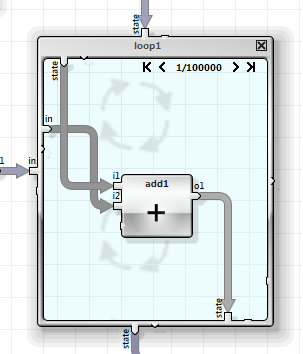
Fortunately there are parallel algorithms to solve these kinds of problems. In the case of the sum of rows it is called “parallel prefix sum”. This algorithm can be used if the dependency generating operation is associative. ANKHOR detects such a loop and executes it as a parallel prefix sum.
Data Word SIMD Parallelism
SIMD parallelism has been available in CPUs for some years now and the size of the SIMD registers is still increasing. It started with 64 bit and has now reached 256 bit (soon to be 512 bit). ANKHOR uses data word SIMD parallelism in many areas, here are some examples:
- Boolean tables (or columns) are stored in a compressed form using one bit per values. Boolean operations such as “and” or “or” can thus be performed using complete processor words covering many values. Many operations that accept a list of Boolean values can also benefit from this layout using special CPU instructions to find the next non zero bit in a data word.
- Most raster graphics operations in ANKHOR are implemented using SSE2 SIMD instructions thus processing several pixels in parallel.
- Many string operations use SIMD instructions to process several characters in parallel.
- Matrix operations use 256 bit AVX instructions when available to process four double precision numbers in parallel (most complex matrix operations such as multiply, inverse, eigenvalue or factorization also use multiple threads)
Processing Grid
If one machine is not enough there is always the option of spreading the processing over several compute nodes. ANKHOR supports the parallel execution of independent loop iterations on several machines using the “shard” operator.
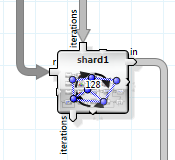
This operator splits the rows of the incoming tables into shards (groups of rows) and distributes them across the compute grid. The results are returned to the invoking machine and combined into the result table.
The parallel execution can be monitored using the Grid Management Console.

Network bandwidth is a critical factor for this kind of parallelism and ANKHOR employs several means to reduce the amount of data that needs to be sent over the network:
- All datasets are compressed before being sent to the executing nodes
- Grid nodes cache input elements to avoid multiple sends when executed more than once
- Shards can have sub shards thus reducing the load on the initially invoking node.
- Common processing data is only sent once (data provided via the state input)
- Results are cached in the compute node and returned on demand, direct forwarding of results from node to node is used if several shards are cascaded
- Prefetching of shards overlaps execution with data transfer, work stealing is used to avoid delays caused by prefetched work in slow nodes.
The compute grid is failure tolerant and grows or shrinks automatically when nodes become available or detached.
Parallel IO
Most IO operations such as reading from a disk, HTTP or FTP network accesses or SQL database request are latency bound. ANKHOR executes these IO operations not on behalf of the processing threads but using an independent set of IO queues. A flowsheet can thus have several hundreds of IO operations pending with a smaller number (e.g. eight) in flight, without blocking the executions of other portions of the operator graphs.
The result is forwarded to the processing threads as soon as an IO operation completes.
Hidden Processing Pipelines
Some operations are not easily parallelized, but can be broken down into a pipeline of independent operations and thus spread over several threads. One such case is the import or export of compressed data sets (fldb). Reading a data blob from disk is separated into three pipelined threads:
- Reading data from disk (or network)
- Decompress data
- Un-marshal and rebuild data
The threads are loosely coupled using large buffers and thus work undisturbed for the most time.
Background Support Threads
There are several background support threads that work in parallel with the normal execution and perform mainly housekeeping, e.g. for parallel garbage collect, cache flushing or writing to disk, preparation of slab memory, rendering or layout of results.
Having these housekeeping threads running in the background relieves the processing threads from work that can be deferred to points in time when there is less parallelism available in the workload.
Implementation Details
Having enough work available to saturate several processor cores is only half the work. One also has to make sure that the executing threads are not blocking each other. ANKHOR uses an optimized heap manager for parallel memory allocation and various non-blocking synchronization primitives to avoid waits or de-scheduling of threads.
The following chart shows the result of three benchmarking sheets (CUBE, LOG and GRAPH) using parallel or non parallel execution and different levels of optimization for parallel execution in iterations per time interval (higher is better).
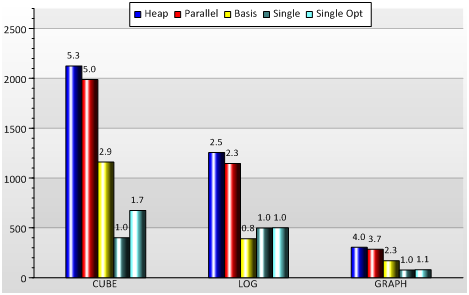
The Single case shows the non optimized execution with a single processor core, the Basis case the same setup with four cores. One can easily observe that simply providing more parallel work does not necessarily increase throughput. The Parallel case shows the result after applying various optimizations for parallel execution (such as lock free synchronization or removal of shared variables). Using the ANKHOR optimized parallel Heap implementation shows an even higher level of parallelism. It is interesting to note that several of the optimizations did also improve the single threaded case SingleOpt.
Conclusion
ANKHOR provides an easy path to use the parallelism available in modern computer architecture without the need to write complex multi threaded programs.