Published on Friday, 11 May 2012.
ANKHOR FlowSheet Analytics is an interactive analytics tool that uses the SAP HANA™ in-memory database technology to provide almost instantaneous user feedback while graphically manipulating flexible data analytics workflows. The advanced analytic capabilities of the SAP HANA™ in-memory database provide the means for running various predictive or analytic operations local to the data and thus with maximum performance.
ANKHOR attends the SAPPHIRE NOW conference, May 14 - 16, 2012 in Orlando. It's the first time we show the brand new ANKHOR FlowSheet Analytics solution supporting the SAP HANA™ in-memory database. Check the schedules at the SAP HANA Demo Pod or the D&T Campus - Micro Forum for a live demo or contact us to schedule a private demo.
Or: The Adventure Park of Data Analytics and Data Visualization
Written by Stefan Herr
on Wednesday, 02 May 2012.
 One of the big current challenges in the computer industry is how we can make the power of the modern multi-core CPUs available to a large audience. Many attempts center on improving and extending existing procedural programming languages or shifting towards paradigms that are friendlier to parallel execution, like functional or dataflow programming. Unfortunately, most of them only address trained programmers and computer scientists and usually require a complete upfront design of the desired solution for the problem at hand.
One of the big current challenges in the computer industry is how we can make the power of the modern multi-core CPUs available to a large audience. Many attempts center on improving and extending existing procedural programming languages or shifting towards paradigms that are friendlier to parallel execution, like functional or dataflow programming. Unfortunately, most of them only address trained programmers and computer scientists and usually require a complete upfront design of the desired solution for the problem at hand.
So what about domain specialists in areas like advanced data analytics (e.g. data mining), data visualization or financial analysis (e.g. business intelligence and financial controlling), who require (and thus are often used to) more intuitive approaches and tools to solving their problems?
Even better: wouldn’t it be great if there even was a way enabling practically “everyone” to easily create solutions for their everyday computing problems, harnessing the full power of parallel programming, without the need to write a single line of code?
Interestingly, there is already a large group of people who unconsciously write parallel dataflow programs every day without being aware of it: I am talking about the users of spreadsheet applications like Excel or Calc (which is part of Open Office). Unfortunately, spreadsheets are afflicted with 5 major problems, so this choice can turn out to be a dead-end street for many.
What are these problems, and is there a way to get out of this trap? Can we bring back the fun into mining information from our data?
I recently had a problem explaining various image filters and decided to try a different way of visualizing the result. So instead of simply applying the filter and generating a series of images, I rendered a set of 3D images of the resulting image using the brightness as the height of a mesh.

Last week I had to use a customers tool which starts RTSP sessions in a video on demand network. This tool dumped its logging information into a text file which I had to analyze after each run. The logfile got bigger and bigger and it became more and more inconvinient to find the interessting places. And if that wasn't enough, the log contained a lot of unuseful message lines ( at least for my job ).
To get an idea about the amount of data : the tool produced ~ 500 lines per second.
So I decided to create a little FlowSheet which should support me a little bit.
Web pages provide a plethora of information and mineable data. Unfortunately most of them are not using the XML based XHTML but the classic HTML. Therefore we decided to extend the ANKHOR XML parser to accept most HTML content.
With this extension it is now quite simple to e.g. extract all <img> references from a web page and convert it into a table.
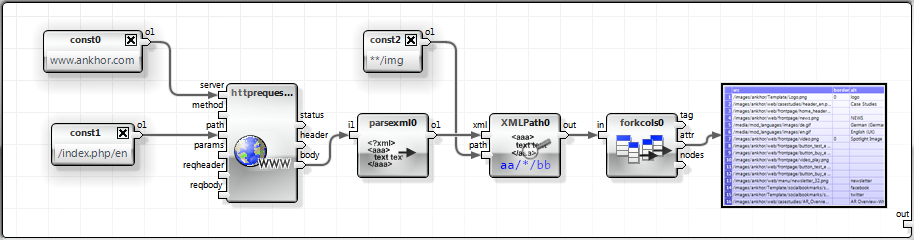
I have created a simple web crawler for testing purposes that walks through all reachable documents on a given domain starting at the root. It uses a while loop to iterate through the access depth. A HEAD request is executed in parallel for all resources that are reachable at this level and have not been accessed in one of the iterations before.